B*-Baum
10. Juli 2014
Keine sorge, soviel komplexer ist der B*-Baum gar nicht.
Wir nehmen die gleiche Tabelle wie beim B-Baum, nur mit etwas weniger Einträgen.
Unterschiede:
Kurzform:
- Datensätze / Werte stehen nur in den Blättern
- Datensätze / Werte werden in die Blätter kopiert
- minimale befüllung der Knoten: 50% (eigentlich 2/3, aber ignorieren wir)
Ausformuliert:
- Das man nicht mehr direkt von einem Knoten aus nach unten zeigt, sondern von einem extra „Element“, welches komplett leer ist
- Das Element was in eine Wurzel / Knoten nach oben gezogen wird, muss dennoch weiterhin in den Blättern vorhanden sein. Sprich es ist doppelt vorhanden. Grund dafür: Nur die Blätter haben im B*-Baum echte Werte.
- THEORETISCH: soll der B*Baum zu 2/3 gefüllt sein. Ist laut unserem Script aber nicht so. also am besten einfach ignorieren (lol)

Der ganze Anfang ist komplett identisch wie beim B-Baum
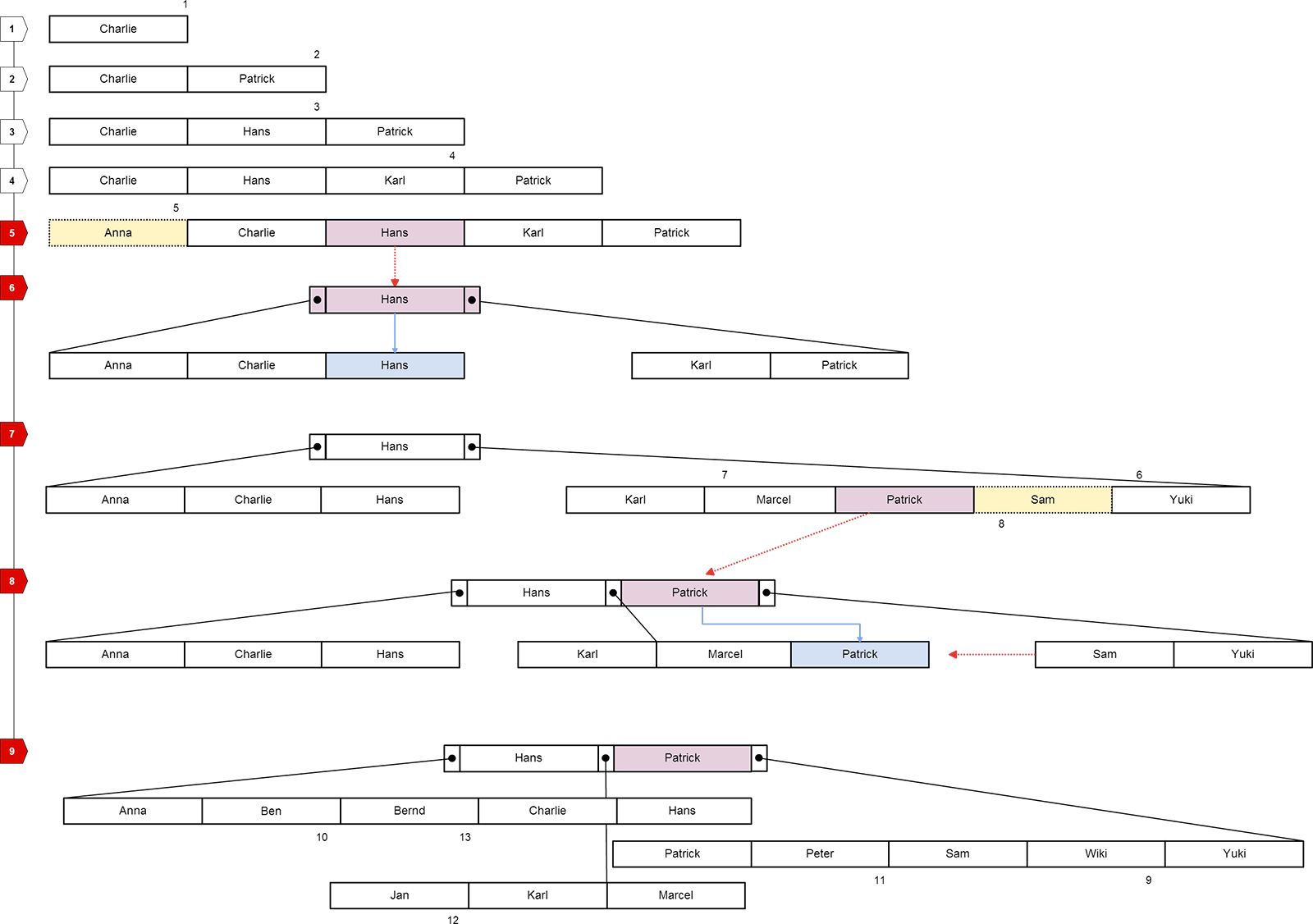

noch einmal zusammengefasst:

Unser Baum besteht nur aus einer Wurzel ebene, und einer Blätter ebene.
Somit ist dies ein ein B*Baum(2,2)
Würde dieser Baum noch mehr werte nach weiter unten bekommen, würde die mittlere Ebene wie die Wurzel aussehen.
Und alle Werte in den Mittleren Knoten müssten mit in die unteren Blätter kopiert werden.