RAID = „Redundant Array of Independent Disks“ (Redundante Anordnung unabhängiger Festplatten)
Ein RAID-System dient zur Organisation mehrerer physischer Festplatten eines Computers zu einem logischen Laufwerk, das eine höhere Datenverfügbarkeit bei Ausfall einzelner Festplatten und/oder einen größeren Datendurchsatz erlaubt als ein einzelnes physisches Laufwerk.
Quelle: wiki
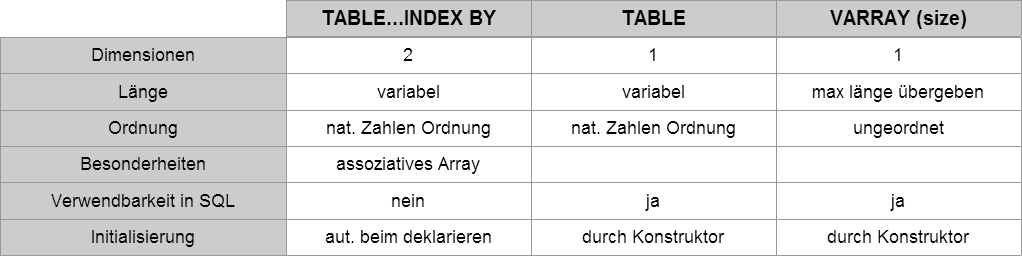
physische Laufwerke = sind CD’s, DVD so wie Festplatten, SSD (Hardware)
logische Laufwerke = sind Partitionen auf einem Speicher (Festplatte), und können getrennt behandelt werden
Redundanz = das vorkommen doppelter Daten
RAID Versionen
Raid 0
- Festplatten werden gestriped
Vorteile
- viel speicher
- sehr schnell
Nachteile
- beim ausfall einer Platte, sind die restlichen Daten unbrauchbar
Raid 1
- die Festplatte wird 1:1 gespiegelt
- normale geschwindigkeit
Vorteile
- sehr sicher, da ja alles doppelt vorhanden ist
- beim Ausfall einer Platte, ist immernoch eine komplette kopie vorhanden
Nachteile
- weniger speicher verfügbar (da ja alles doppelt vorhanden ist)
Raid 1 + 0 > 0 + 1
Raids kombinieren: 1 + 0 ist besser als 0 +1
- Festplatten werden gespiegelt UND gestriped
1 + 0 werden mehrere festplatten 1 : 1 gespielt, und dann gestriped.
Wenn jetzt eine Festplatte aus einem Raid 1 Bereich ausfällt, so ist im selben Bereich noch eine 1:1 kopie verfügbar.

0 + 1 werden mehrere festplatten gestriped und dann erst gespiegelt.
Wenn jetzt eine Festplatte aus dem Raid 0 Bereich kaputt geht, sind alle anderen Festplatten in diesem Raid system unbrauchbar(!)
Und sollte jetzt (siehe beispiel) im zweiten Raid 0 eine andere Festplatte mit anderen Daten Defekt sein, so wären alle Raids unbrauchbar.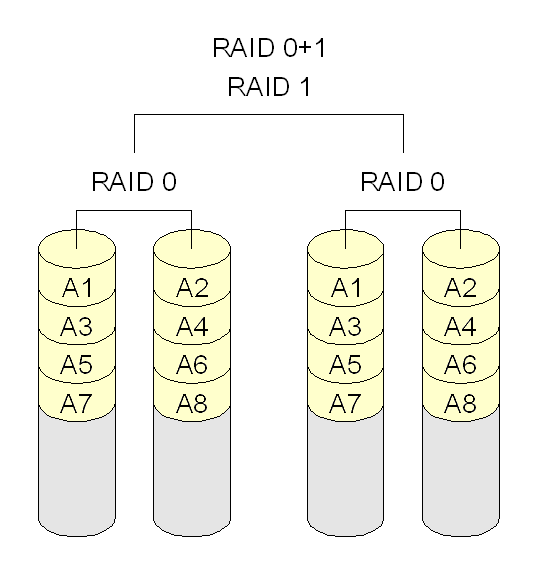
Raid 2-4 sind unwichtig
/
Raid 5
(aktueller und zur zeit bester Standard)
- mehrere Festplatten werden gestriped
- keine spiegelung
- verwendet Paritätsstreifen
Vorteile
- Daten-Redundanz
- sehr schnell
- geringe kosten
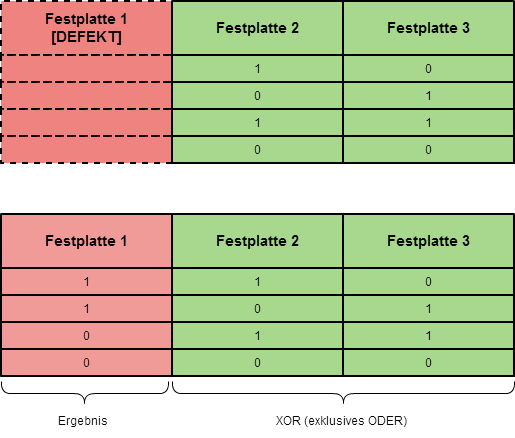
Paritäten dienen der Wiederherstellung von Daten
Parität = ist eine einfache XOR verknüpfung (exklusives ODER)
Die Parität wird immer um 1 verschoben auf der nächsten Festplatte gespeichert.
Denkt jetzt einfach mal an Mathe 1 zurück :D
wenn ihr jetzt nach einem Ausfall noch 2 von 3 Festplatten überhabt, könnt ihr anhand der Paritäten in den restlichen 2 Platten bestimmen, was wiederhergestellt werden muss.