RAID
Posted by pantsu On 16. Juli 2014
RAID = „Redundant Array of Independent Disks“ (Redundante Anordnung unabhängiger Festplatten)
Ein RAID-System dient zur Organisation mehrerer physischer Festplatten eines Computers zu einem logischen Laufwerk, das eine höhere Datenverfügbarkeit bei Ausfall einzelner Festplatten und/oder einen größeren Datendurchsatz erlaubt als ein einzelnes physisches Laufwerk.
Quelle: wiki
physische Laufwerke = sind CD’s, DVD so wie Festplatten, SSD (Hardware)
logische Laufwerke = sind Partitionen auf einem Speicher (Festplatte), und können getrennt behandelt werden
Redundanz = das vorkommen doppelter Daten
RAID Versionen
Raid 0
- Festplatten werden gestriped
Vorteile
- viel speicher
- sehr schnell
Nachteile
- beim ausfall einer Platte, sind die restlichen Daten unbrauchbar
Raid 1
- die Festplatte wird 1:1 gespiegelt
- normale geschwindigkeit
Vorteile
- sehr sicher, da ja alles doppelt vorhanden ist
- beim Ausfall einer Platte, ist immernoch eine komplette kopie vorhanden
Nachteile
- weniger speicher verfügbar (da ja alles doppelt vorhanden ist)
Raid 1 + 0 > 0 + 1
Raids kombinieren: 1 + 0 ist besser als 0 +1
- Festplatten werden gespiegelt UND gestriped
1 + 0 werden mehrere festplatten 1 : 1 gespielt, und dann gestriped.
Wenn jetzt eine Festplatte aus einem Raid 1 Bereich ausfällt, so ist im selben Bereich noch eine 1:1 kopie verfügbar.

0 + 1 werden mehrere festplatten gestriped und dann erst gespiegelt.
Wenn jetzt eine Festplatte aus dem Raid 0 Bereich kaputt geht, sind alle anderen Festplatten in diesem Raid system unbrauchbar(!)
Und sollte jetzt (siehe beispiel) im zweiten Raid 0 eine andere Festplatte mit anderen Daten Defekt sein, so wären alle Raids unbrauchbar.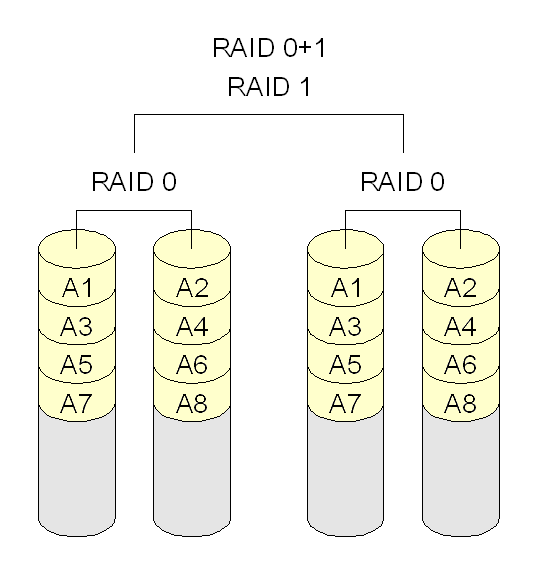
Raid 2-4 sind unwichtig
/
Raid 5
(aktueller und zur zeit bester Standard)
- mehrere Festplatten werden gestriped
- keine spiegelung
- verwendet Paritätsstreifen
Vorteile
- Daten-Redundanz
- sehr schnell
- geringe kosten
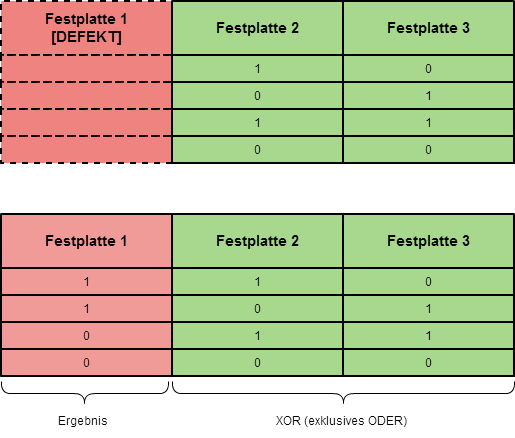
Paritäten dienen der Wiederherstellung von Daten
Parität = ist eine einfache XOR verknüpfung (exklusives ODER)
Die Parität wird immer um 1 verschoben auf der nächsten Festplatte gespeichert.
Denkt jetzt einfach mal an Mathe 1 zurück :D
wenn ihr jetzt nach einem Ausfall noch 2 von 3 Festplatten überhabt, könnt ihr anhand der Paritäten in den restlichen 2 Platten bestimmen, was wiederhergestellt werden muss.
Hibernate – Grundbegriffe
Posted by pantsu On 16. Juli 2014
Hibernate wird auch als Objektrelationales Mapping (kurz: ORM) bezeichnet.
Sprich: Wenn Fragen zum Thema ORM gestellt werden, ist damit das Mapping bzw. Hibernate gemeint.
- Hibernate – Mapping geschieht im XML format
- Hibernate ist ein Framework – speziell für relationale DB
- RDBMS = Relationales DBMS
- Basierend auf Java
- Abfrage durch : Hibernate Query Language (HQL)
- wird mitunter zusammen mit JDBC verwendet
Vorteile:
- übersichtlicher Quellcode
- übertragbarkeit auf andere DBMS möglich
Hibernate arbeitet mit Sessions. Diese müssen explizit gestartet und auch wieder geschlossen werden.
Ebenso muss jede Transaktion mit einem commit() bestätigt, oder rollback() zurückgesetzt werden.
1 2 3 4 5 6 7 | transaction = session.beginTransaction(); //code transaction.commit(); // oder transaction.rollback(); //code session.close(); |
Raid5 – LOL
Posted by pantsu On 15. Juli 2014
Wie wärs mit einem Wasserspender als Maskottchen??
raid 5 – explained – check

Quelle: hier
{kind=link}
5 – Schichtenmodell
Posted by pantsu On 15. Juli 2014
5 Schichtenmodell = 5 Schichtenarchitektur
(man könnte es auch die 5 Schnittstellen nennen)
- Dateischnittstelle
- Pufferschnittstelle
- Interne Satzschnittstelle
- DB – Schnittstelle
- Mengenschnittstelle
Erweitert:
- Dateischnittstelle – Speicherzuordnungsstrukturen
- Pufferschnittstelle – Seitenzuordnungsstrukturen
- Interne Satzschnittstelle – Speicherungsstrukturen
- DB – Schnittstelle – Logische Zugriffspfade
- Mengenschnittstelle – Logische Datenstrukturen
Als Ebene (0) wird die „Geräteschnittstelle“ angesehen.
- Dateischnittstelle – speichern und lesen von Dateien
- Pufferschnittstelle – Ein/Auslagern von Seiten
- Interne Satzschnittstelle – Einordnen von Sätzen in Seiten (z.b. B-Bäume)
- DB-Schnittstelle -Verwalten von Sätzen (Tupeln)
- Mengenschnittstelle – Ausführungspläne erstellen (auf Relationen/Tupel)
COMMENTS
Posted by pantsu On 14. Juli 2014
ihr könnt jetzt mit eurem google+ account – Kommentare und Fragen hinterlassen ^^
Viel Spass dabei~
Berechnungen im B-Baum (MIN / MAX)
Posted by pantsu On 14. Juli 2014
Hier einmal kurz veranschaulicht wie man die Minimalen und Maximalen Elemente im B-Baum berechnet (und aufzeichnet)
– sehr ausführlich –
———————————
B-Baum Typ (2,3) (Berechnung von MIN)
– es müssen MINDESTENS 2 Elemente in einem Knoten stehen
– ausgenommen der WURZEL dessen Anzahl ist egal. Aber es muss mindest. 1 sein.
damit Kinder Knoten gebildet werden können. (Jeder Knoten hat K+1 Kinder)


B-Baum Typ (2,3) (Berechnung von MAX)
– jeder Knoten muss komplett gefüllt sein (K*2 Knoten => 2*2 = 4)
– Die Wurzel muss jetzt natürlich auch komplett befüllt sein.
– es muss über die Höhe 3, für jeden Knoten k+1 Kinder geben



EDIT
Ich habe gerade noch eine kleine Brücke gefunden. Für alle die sich das keine langen komplexen Formeln merken können.
MIN
Ihr nehmt einfach die vorherige anzahl an Knoten, und nehmt dann [ Knoten * Knoten + Knoten ]
Und am ende müsst ihr diese nur noch mit der Anzahl der Elemente in einem Knoten Addieren. (funktioniert nur bei der berechnung von MIN)
Berechnung Typ (2,3)
Die Wurzel hat einen Knoten. also:
1*1 +1 = 2 -> 2 knoten auf der höhe 2
jetzt nehmt ihr das ergebnis von der Wurzel, und rechnet damit weiter
2*2+2 = 6 -> 6 Knoten auf der höhe 3
usw.
6*6+6 = 36 -> 36 knoten auf der höhe 4 (ab hier macht das Zeichnen dann auch keinen spass mehr : )
—
Für MAX kann man das ähnlich darstellen: im Typ (2,h)
es ist einfach immer MAL 5 => denn 2*2+1 (Knoten * 2 + 1 Kind)
[ ( KNOTEN * 5 ) ]
Wurzel : max 4
4 * 5 = 20
20 * 5 = 100
100 * 5 = 500
500 * 5 = 2500
—–
Ich glaub ausführlicher geht es nicht mehr :)
Wenn dennoch fragen offen geblieben sind: einfach anschreiben!
——
HAUSAUFGABEN
Ich höre schön das stöhnen und seufzen aus dem Hintergrund ^^
Aber die beste Art etwas neues zu lernen, ist nun mal das mehrfache anwenden.
Die Aufgabe ist auch ganz simpel: berechnet die folgenden Typen von B-Bäumen mal per Hand durch. (und macht dabei auch gerne Skizzen)
Und zur Kontrolle habt ihr hier direkt alle Lösungen (>“<)
1) B-Baum Typ (2,6) – min
2) B-Baum Typ (3,4) – max
3) B-Baum Typ (3,4) – min
4) B-Baum Typ (2,5) – max

Linksammlung [wird editiert]
Posted by pantsu On 13. Juli 2014
Klassendiagramme – sehr ausführlich – deutsch
UML Klassendiagramm – kurz zusammengefasst
[16.07-14]
Galileo Channel auf Youtube (z.b. videos zum thema hibernate)
schlanke übersichtliche Java Seite (Grundlagen- englisch)
Hibernate für sehr ambitionierte (ausführlich – englisch)
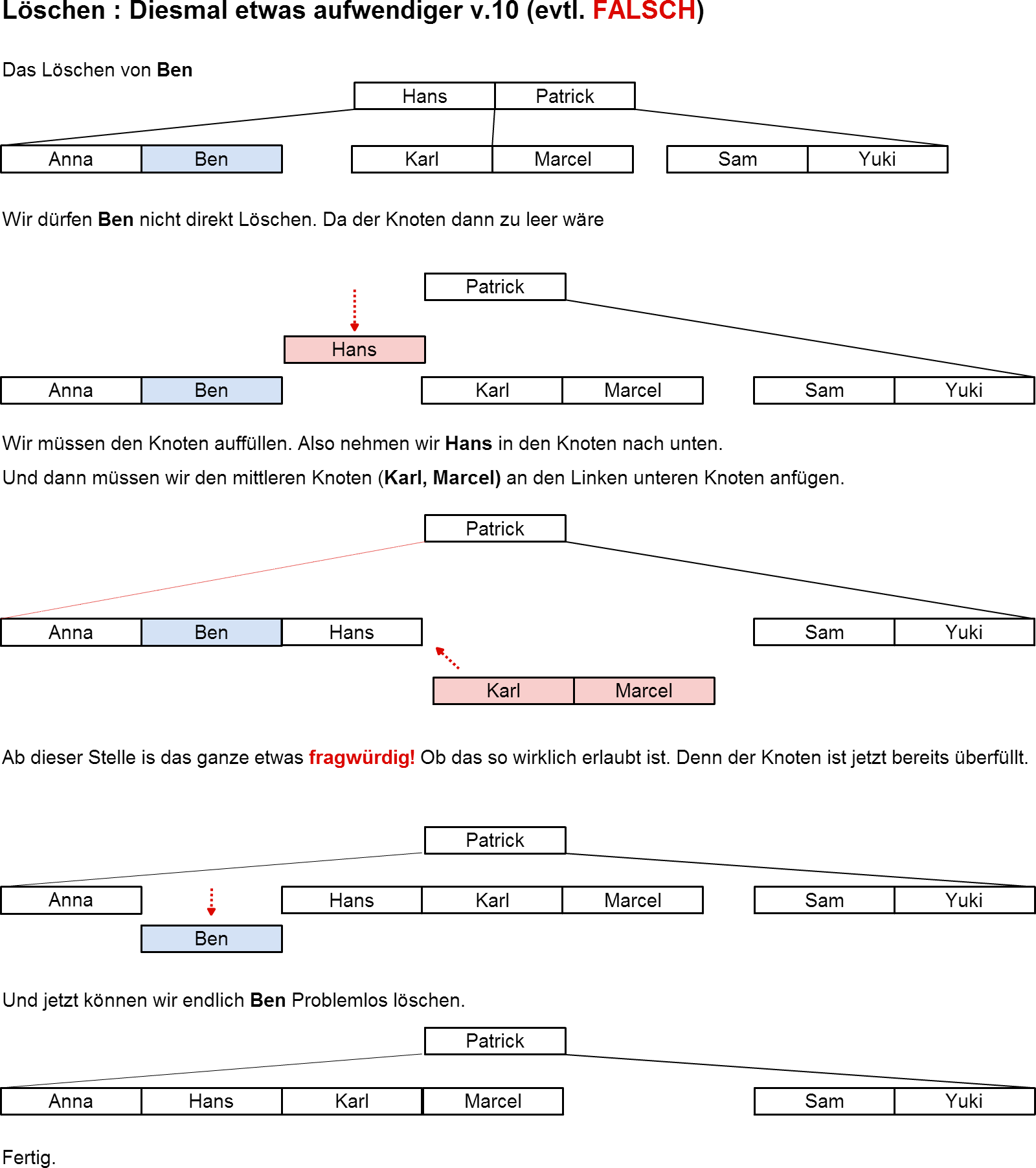
Löschen im B-Baum
Posted by pantsu On 13. Juli 2014
So jetzt wird es lustig… viel spass…!
[Wir gehen hier grundsätzlich von einem B-Baum vom Typ(2,h) aus ]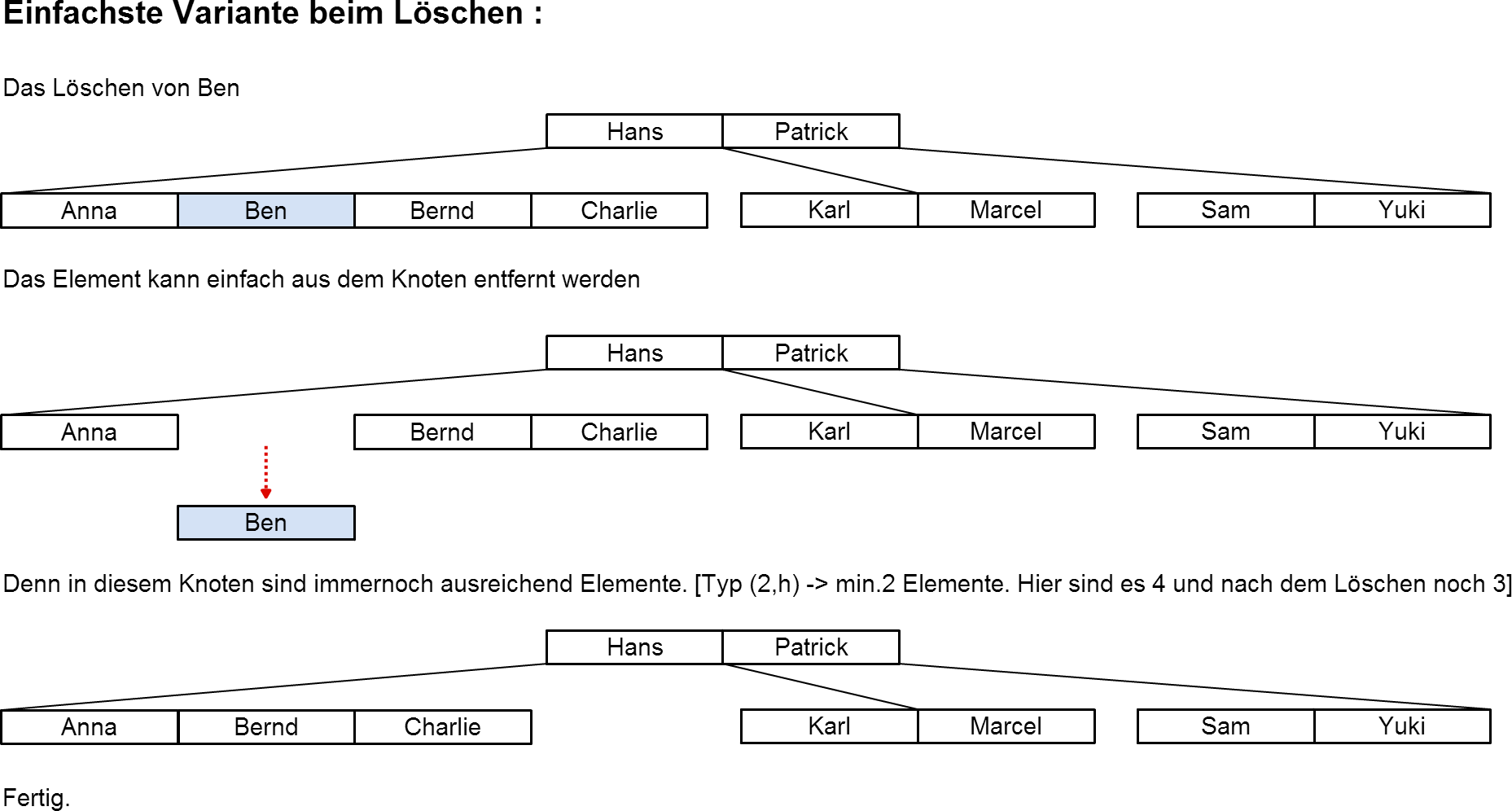

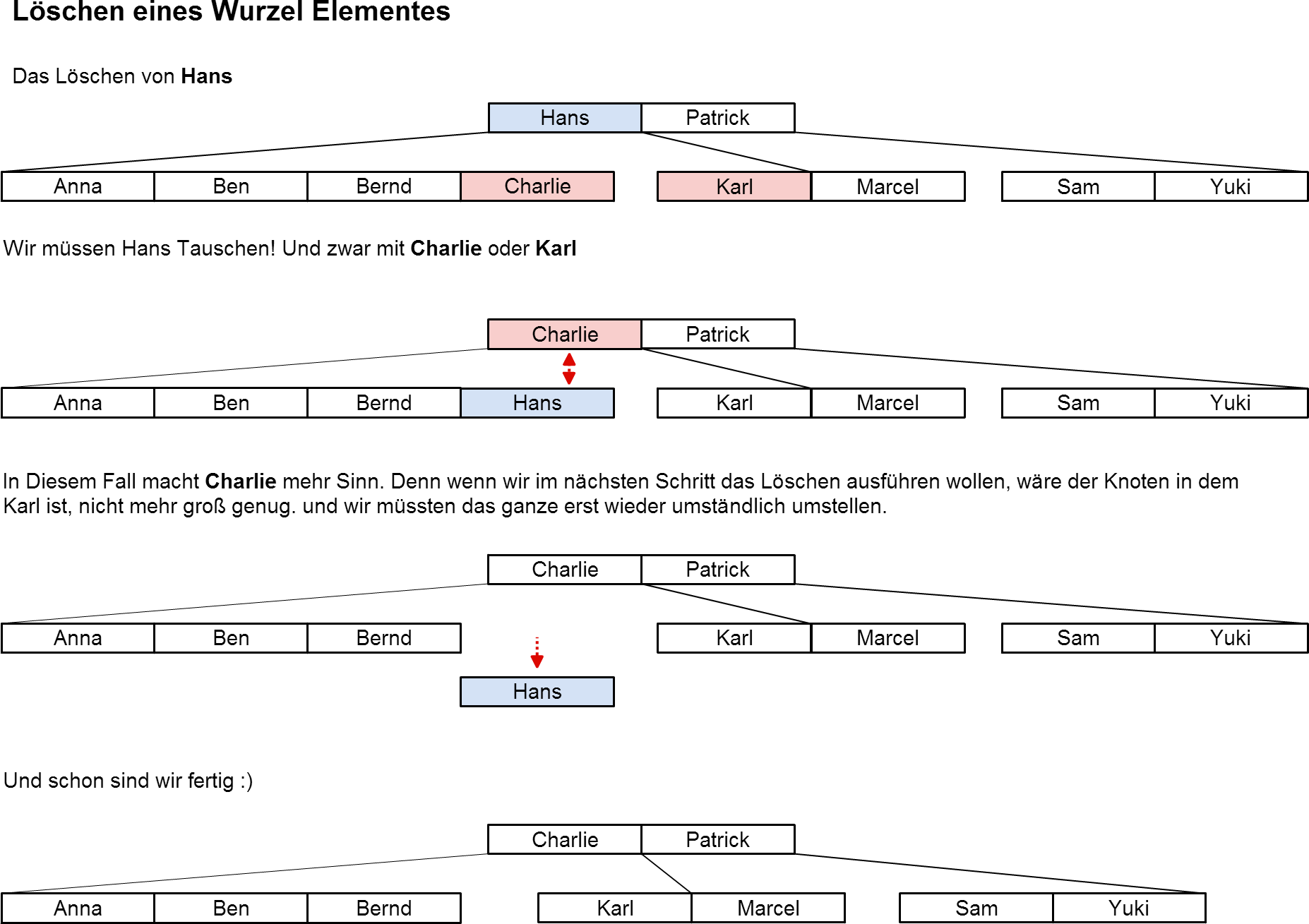
INFO

Kollektionen in PL/SQL
Posted by pantsu On 12. Juli 2014
Kollektionen besitzen mehrere Elemente des gleichen Datentyps (homogon)
Man kann sie sich auch als Array vorstellen.
Wir unterschieden hierbei 3 verschiedene Kollektionen:
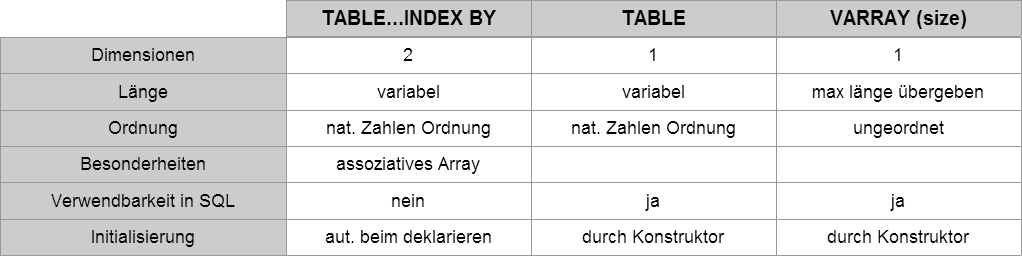
Laut PL/SQL – kurz & gut hat auch das assoziative Array nur eine dimension. Aber ich halte mich jetzt einfach mal ohne Gewähr an die Vorlage.
Ausformuliert:
TABLE.. INDEX BY :
ist ein zweidimensionales – assoziatives – Feld mit variabler Länge. Mit (ungeordnete) Schlüsselwerten indexiert. (assoziatives array)
TABLE:
ist ein eindimensionales Feld mit variabler Länge. Es ist nach natürlichen Zahlen geordnet zugreifbar.
VARRAY:
ist ein eindimensionales Feld mit maximaler Länge
Was ist PL/SQL ?
Posted by pantsu On 12. Juli 2014
„PL/SQL ist eine Prozedurale Erweiterung für die strukturierte Abfragesprache SQL“
oder auch
„Erweiterung der Datenbanksprache (SQL) um prozedurale Programmierung“
SQL ist Mengenorientiert. Das Ergebnis ist immer eine Menge von Tupeln.
WAS fehlt SQL um vollständige Anwendungssysteme zu Programmieren?
- man kann nicht gezielt einzelne tupel bearbeiten
- man kann keine schleifen definieren (oder rekursion.. etc)
- variablen deklarieren
Wozu brauch man PL/SQL?
- um komplexe erweiterungen für SQL zu ermöglichen. Unter verwendung von variablen, methoden, und kontrollstrukturen
- zu steuerung von selbst programmierten abläufen
- wiederverwendbarkeit von Funktionen und Prozeduren
zu deutsch:
Man kann in SQL nur umständlich über Zwischentabellen diverse Abfragen machen. Was sich mit schleifen und Variablen wesentlich einfacher umsetzen ließe. Es gibt einen direkten zugriff auf die Datenbank. Und man kann seine selbstgeschriebenen Prozeduren und Funktionen wiederverwenden.
WAS HAT PL/SQL ZU BIETEN?
[ADA nachempfundene Sprache] (ähnlich wie die fragen zuvor)- Variablen, Konstanten und Datentypen
- Kontrollstrukturen [Bedingungen (IF, CASE, EXIT) und Schleifen (WHILE, FOR, LOOP)]
- Blöcke, Prozeduren, Funktionen und Pakete (anonym block, PROCEDURE, FUNCTION, PACKAGE)
- Fehlerbehandlung (EXCEPTION)
- Einbettung von SQL-Anweisungen
Wie ist PL/SQL angepasst an SQL?
- Die DT sind identisch
- SQL kann normal eingebettet werden
- a) lesen: SELECT INTO <pl var>
- b) schreiben: INSERT INTO VALUES (<pl var/wert>..)
- c) Menge aus DB lesen: DECLARE CURSOR Name IS SELECT .. etc
- Die Funktionen des DBMS werden verwendet
- a) erweiterbarkeit von SQL durch in der DB gespeicherte Prozeduren und Funktionen (CREATE, DROP)
- b) Rechte Verwaltung in Mehrfachanwender umgebung
- c) Ausführung meist auf dem server
Was ist der Nachteil von PL/SQL?
- PL/SQL ist proprietär zum Oracle DBMS
- zu deutsch: Die Programme laufen nur für Oracle-Datenbanken. Wechselt man die Datenbank, wird es relativ kompliziert, die Anwendung umzuschreiben.
Weitere umfassende Informationen über PL/SQL findet ihr hier
Es würde jetzt zu weit gehen, wirklich jede Kleinigkeit hier neu zu formulieren.